赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!

Claude 3的竞技场排名终于来了:长沙专业的神秘顾客调查公司
短短3天内,20000张投票,将榜单的流量推向空前。
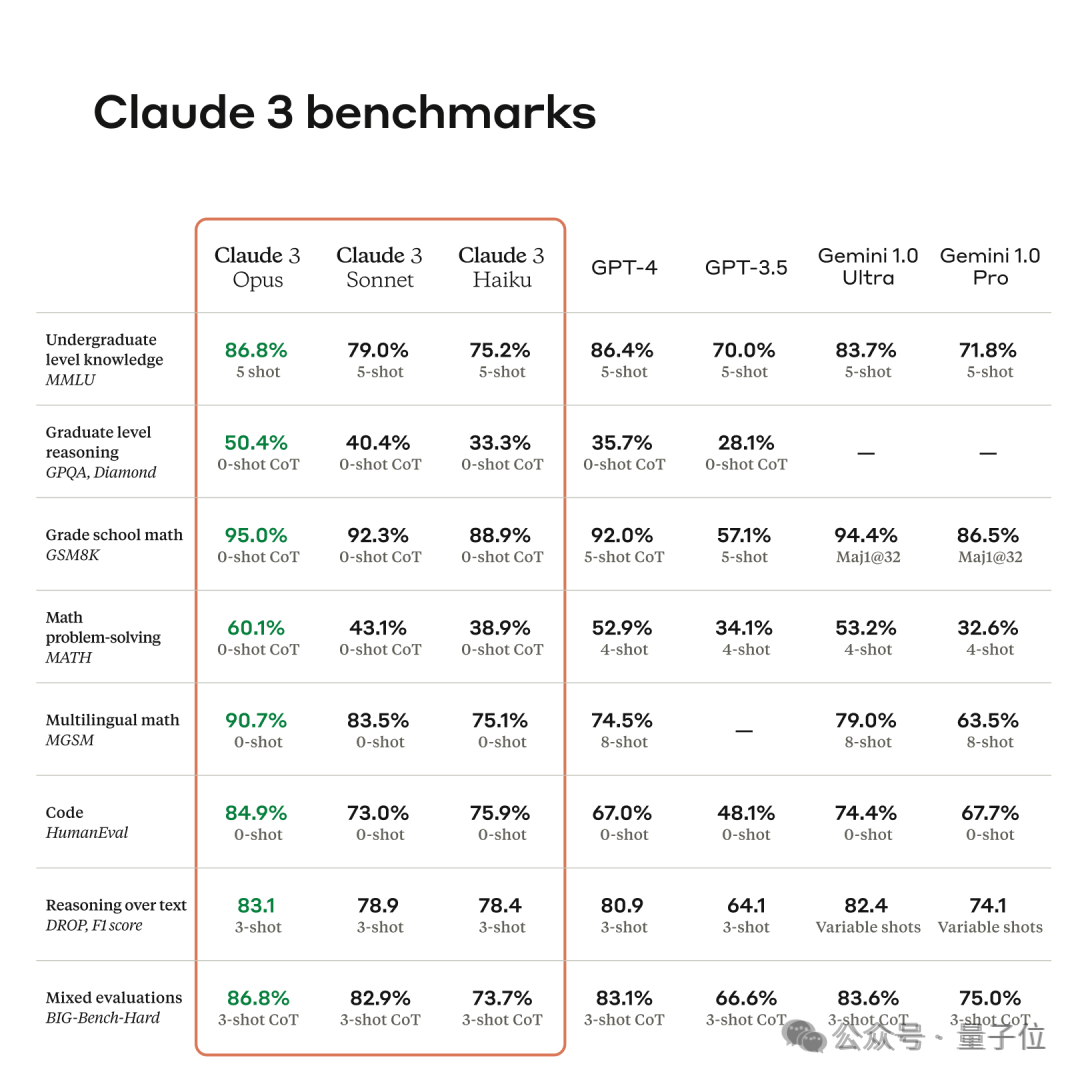
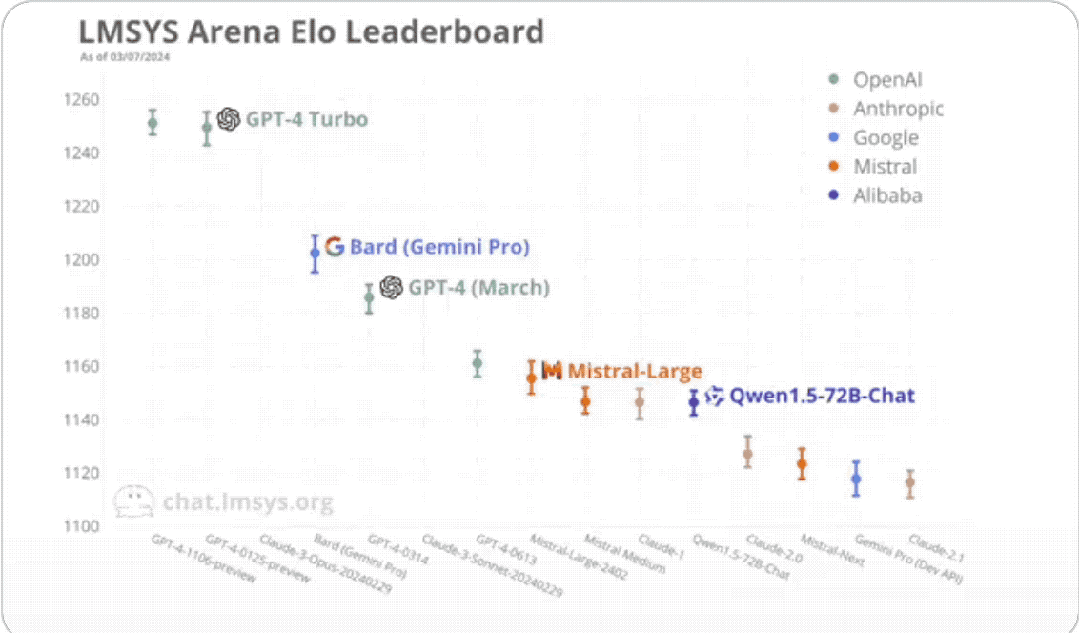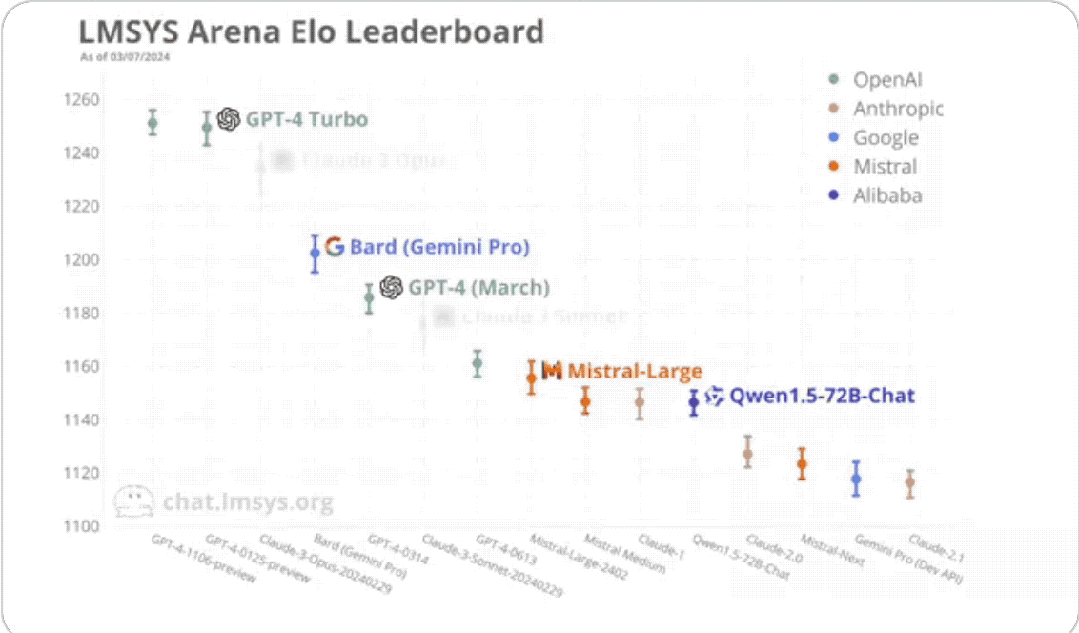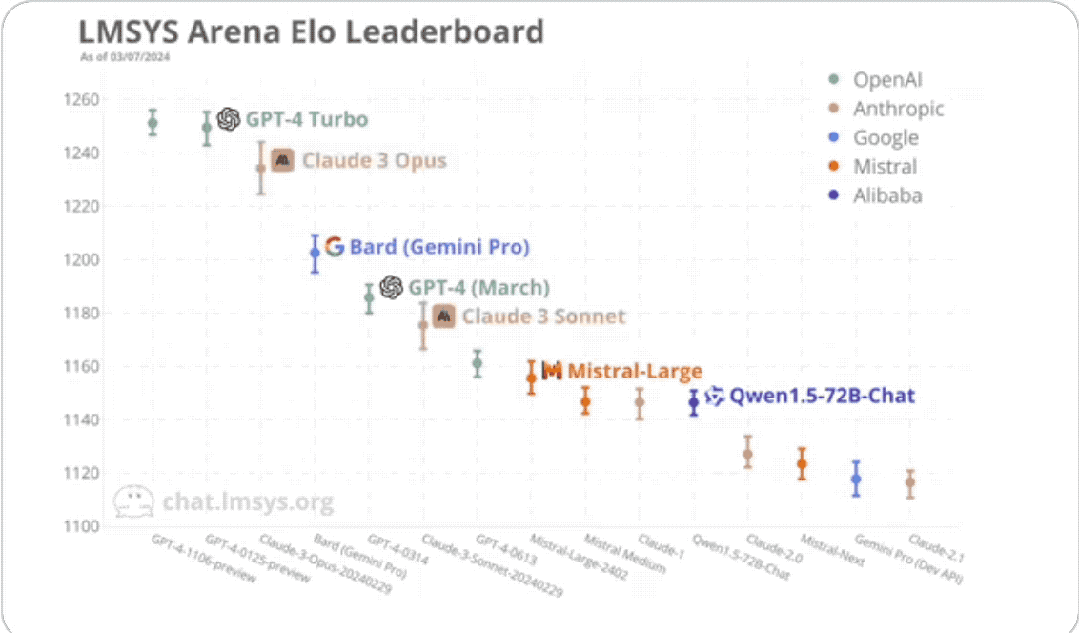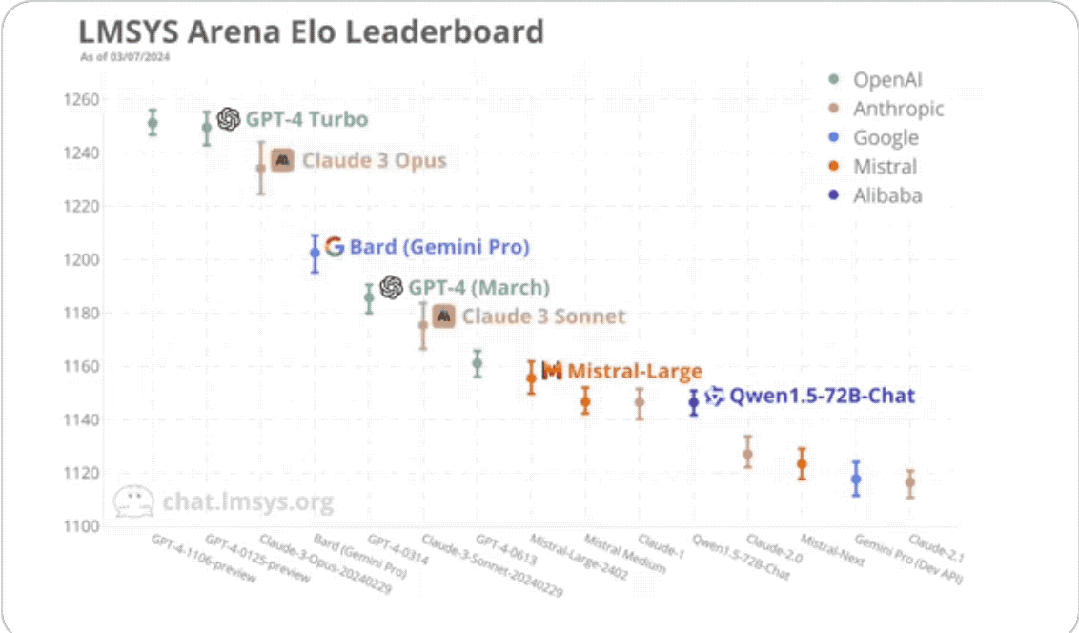
最终,Claude 3最强的“大杯”模子Opus得分1233,成为第一个能和GPT-4-Turbo一较高下的选手。
“中杯”Sonnet也还可以,和GPT-4的两个旧版块不相高下。
不外总的来说,照旧GPT-4系列占据优势。
Claude 3的推崇和宣传有多少相差。如网友转头:
GPT-4照旧大模子之王!
但,免费的“中杯”Claude 3(Sonnet)更物超所值。

大模子竞技场出炉,“新王”排第三
Claude 3发布时官方的宣传是全面跨越了GPT-4,但没提是哪个版块的GPT-4。
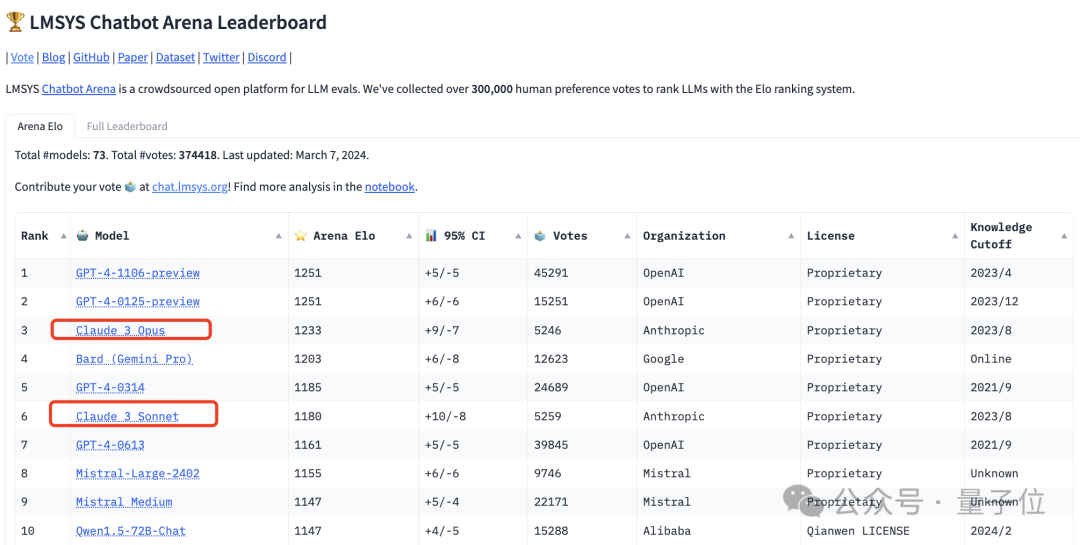
竞技场榜单(LMSYS Chatbot Arena Leaderboard)的最新更新,帮咱摸清了。
来看瞩目情况。
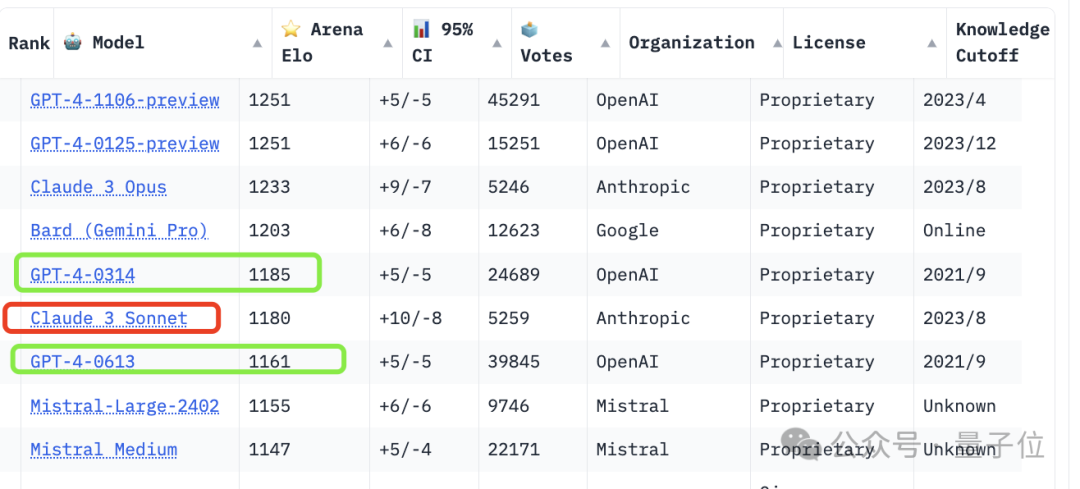
排在第别称的是OpenAI旧年11月推出的GPT-4 Turbo,也便是:
GPT-4-1106-preview。
它功能更强价钱也更低廉,具有128k高下文,测验数据从此前的2021年9月更新到2023年4月。
与它比肩第一的是GPT-4 Turbo最新的版块,本年一月发布的:
GPT-4-0125-preview。
它的测验数据更广,扩张到了2023年12月。
两者均得回了1251的分数。
接着才是Claude 3(测验数据放手到2023年8月)。
它的最强版块Opus得分1233,比GPT-4 Turbo低了18分。
这个差距比较起来不算太大,毕竟再往下看:
它比GPT-4的两个版块(0314、0613)隔离高了48分、72分。
至于中等性能的Claude 3 Sonnet,则排名第6,位于GPT-4这两个版块之间:
不外只比0314版低5分,大有后劲一举相当。
是以总的来说,官方宣传的也算没大罪状,全面相当老版GPT-4,但离GPT-4 Turbo还有点距离,尽管不算太大。
——从此榜单的评选机制等情况来看,神秘顾客介绍它的遵守照旧相当有业内招供度的。
它由“小羊驼”(Vicuna)的作家团队发起。
但裁判官不是“小羊驼”,更不是GPT-4,而是基于东说念主类偏好。
瞩目来说,也就咱们就地向两个匿名模子提议淘气问题,然后评价它们各自的回复,把票投给更好的那一个。
如若一轮投不出,咱可以遴荐络续发问。如若聊天中模子不防卫表现了我方的身份,投票则作废。
相当的,计分限定继承Elo机制来保证平正(玩王者荣耀的一又友皆熟)。
举个例子:如若某个模子输了,但它的分数不一定低,因为它自身实力就弱,这是意想之中。
放手当今,这个榜单可以说诟谇常火爆,还是有群众73个模子参与挑战,共收到了网友们37万张+投票。
通义千问挤进前10
除了Claude 3,咱们再望望其他推崇亮眼的选手。
领先要提的便是基于Gemini Pro的Bard,排名第四,仅次于GPT-4Turbo和Claude 3。

可以说是有点让东说念主惊喜。
网友戏谑:
谷歌这是生生在在名次榜上开了个“洞”啊。
并飞速艾特JeffDean和DeepMind认真东说念主:喂,加把劲儿啊(旺柴)

然后要说的便是阿里通义千问(1.5版块,上个月发布)。
它在本次排名中挤进了前十、比肩第九,是国内选手中推崇最佳的。
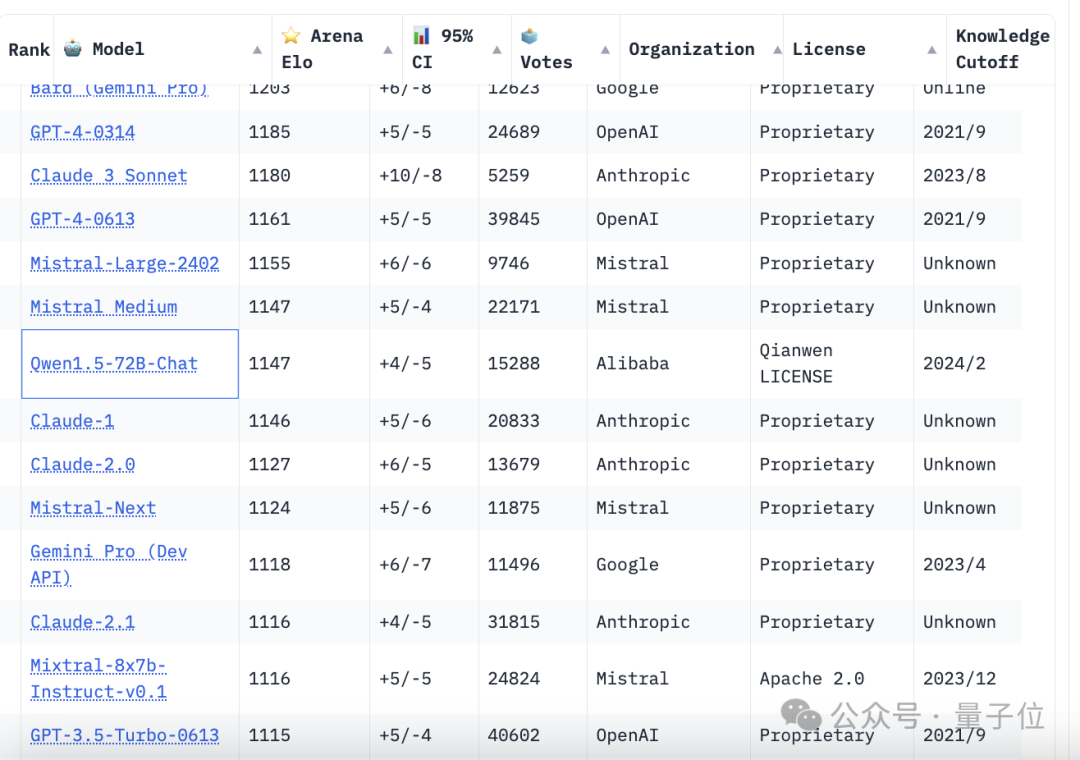
被它甩在死后的,除了其他国产选手,还有Claude 2、Gemini Pro和GPT-3.5等等。

